
存储芯片







 关于尧云
关于尧云 业务咨询
业务咨询 微信客服
微信客服 联系我们
联系我们



【尧云课堂】大容量、高可靠性的pMLC NAND固态硬盘
前情提要
在科技不断发展、对产品的要求持续提高的背景下,主流的TLC/QLC、SLC和MLC NAND、全盘pSLC NAND又存在种种因素无法满足当今市场的需求。于是pMLC固态硬盘作为介于TLC和PSLCD的折中技术方案,使存储模式同时实现了大容量和较高数据可靠性。
今天就来了解一下pMLC在实际性能上的表现。
01
技术方案
Technical Scheme

固态硬盘产品数据存储的可靠性,与NAND的质量直接相关。实际固态硬盘产品下, NAND的PE cycle是该项最直接指标体现。实际产品的PE cycle与NAND介质的老化磨损速度以及该固态硬盘控制器的纠错能力相关。
老化磨损
pMLC模式下cell的实际老化磨损情况与TLC模式基本一致,原因在于其与绝缘层磨损次数相关,而绝缘层磨损次数取决于erase/program的模式。pMLC模式下NAND仍然采用TLC erase和program,所以其磨损的程度与TLC一致。
进一步分析,NAND磨损的根本原因在于cell中电子隧穿会造成用以隔断的绝缘层损耗。NAND中cell的基本结构如下图所示。NAND的read、program、erase操作都会带来不同程度的电子隧穿,其中erase的影响最大,因为其施加的电压高且时间长,在其电子穿过绝缘层时必然会造成一定程度损耗;program的影响次之,因为其也会有电子穿过绝缘层;而read影响则基本可以忽略不记。
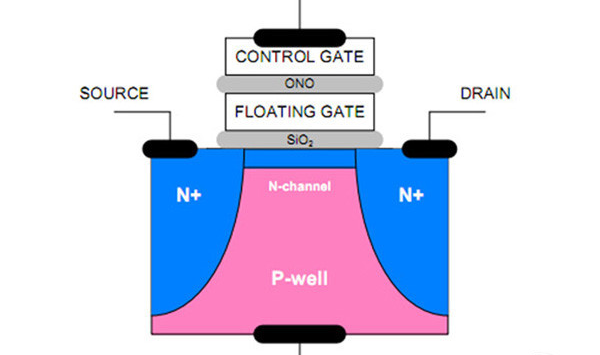
采用“模拟”方案的pMLC模式时,NAND的read、program、erase操作对cell的 老化磨损的速度基本相同。
纠错能力
在LDPC的ECC支持下,我们针对部分市场主流的3D TLC NAND进行了综合老化测试。实验证明这些NAND的low、mid和up page的数据存储的可靠性和保持性是存在一定差距的。采用类fast page mode方式屏蔽了最差level的page,将会有效提高整体NAND在相同强度ECC下的可靠性和数据保持性,从而可以确保数据安全的前提下达到更高的PE cycle。
以某国产NAND颗粒X1的一组实验测试数据为例,其在老化磨损3000次PE时,low和up page的RBER分别为mid page的65.7%和73.8%。也就是说在相同cell磨损情况下,low和up page比mid page的ECC强度需求更低。

在同样ECC纠错能力的LDPC支持下,基于该NAND颗粒pMLC模式,可以较原TLC模式将PE cycle提高1.1倍。
02
读写性能
Literacy
读性能
固态硬盘的存储介质为NAND Flash,其读性能上远好于写和擦除。pMLC模式对固态硬盘整体的读性能提升不明显,总体读性能变化不大。
写性能
固态硬盘的写性能,取决于存储介质NAND program操作的并发程度和速度。其中并发程度与控制器能力、实际盘片贴的NAND颗粒数目和型号相关;program的速度取决于NAND IO总线的频率和cell program的时间。pMLC模式下, NAND颗粒数目和型号未有变化,最终对写性能产生变化影响的主要因素是写数据传输和编程时间。
在NAND page program时,写操作可以被分为两个部分,一是数据的data in,即数据通过IO总线从控制器到达NAND内部register的操作。二是cell program,即数据的从NAND内部register被program到NAND实际存储单元的操作。如下图所示,在相同Channel下的多个NAND die的数据在IO总线上的传输是串行的,而cell program则可以独立并行执行。其中IO总线的传输速度由其频率决定,cell program的时间则由NAND决定。
这就意味着,最终该channel下的极限program的性能受限于如下两者中差的那个:
多die数据在IO总线上串行传输性能。
多die并发执行cell program的性能。

如上图所示,在channel内die并发度较高,IO总线性能较低,cell program速度较快时,通常写性能最终受因素1影响;

否则,写性能最终受因素2影响。具体见上图所示。
pMLC模式下的性能与其实现方案有关。在TLC中剔除一个level的page,当前有两种处理方案:
第一种是采用正常TLC的program命令序列,被剔除的page采用填充dummy数据program,这种方式会导致channel的IO总线的数据有效性降至原来的2/3。并且由于原TLC模式下一次one-pass program可以实际写入更多的page,在cell program上也同样存在1/3的性能下降。NAND的写性能较TLC模式有一定程度的下降。
第二种是改变TLC的program命令序列,只下发未剔除的两个level page的数据到NAND。这种方式可以确保所有的IO总线资源均用于传输有效数据,总线的数据有效性与原TLC模式保持一致。但原TLC模式下一次one-pass program可以实际写入更多的page,在cell program上性能依然存在1/3的下降。此时如果channel内并发度的die个数较高,NAND的写性能与TLC模式可以保持一致。
总体上,采用“模拟”方案的pMLC模式对NAND program的效率有一定程度的下降。但由于常见的TLC固态硬盘均需要引入pSLC cache来提高可靠性和性能,而pMLC模式可以降低甚至取消对pSLC cache的依赖,所以该模型下的固态硬盘可以确保写性能总体与原TLC模式保持一致。
03
测试方法
Test Method
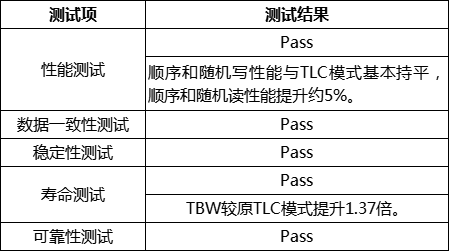
为了完整的验证PMLC模式下固态硬盘的产品稳定性、可靠性和性能等情况,尧云科技进行了全面的测试验证。主要测试用例包括如下:

效果
经过实验室严格测试,相同型号的固态硬盘产品在pMLC模式下的测试结果满足需求。

固态硬盘的销毁方案
随着中国数字经济的高速发展,固态存储硬盘(SSD)在越来越多的新兴应用场景被使用。整个市场都在追捧存储的性能、容量以及寿命,却忽略了数据本身的重要性,数据表明,7成以上的数据泄露是由于未及时销毁处理淘汰、废弃的存储设备造成的。
我司针对老化、过时以及紧急情况下的需要对SSD进行的销毁动作,提供两种销毁类型:硬销毁和软销毁。
硬销毁也叫物理销毁,是指SSD通过特定硬件电路,在识别到用户物理销毁操作后,通过高压,大电流的方式对存储介质进行彻底的破坏过程。下面是对一片FLASH颗粒进行的物理销毁,结果见下图所示
软销毁是通过更改固件的方式将SSD中的所有数据擦除。当用户触发软销毁指令后,SSD将进行数据销毁处理。处理过程中若发生异常掉电,盘会在下次上电后继续执行销毁动作,直至将SSD的所有用户数据抹去。
01
技术方案
Pure simplicity

1956年IBM公司制造出第一块机械硬盘,为之后固态硬盘的衍生提供了土壤。在数据擦除方面,机械硬盘由于可以覆盖写的电气特性,通常对其软销毁的方式是全盘进行覆盖写,以达到盘内数据无法通过技术手段进行数据恢复。针对固态硬盘,我司同样有8种不同级别和数据类型的覆盖写功能。
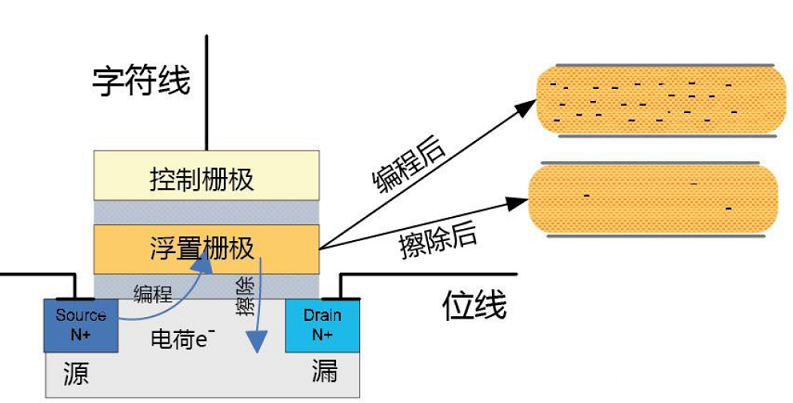
固态硬盘是以NAND FLASH为存储介质。数据在FLASH中是以电荷(electrical charge)形式存储的。电荷的多少,取决于控制门(Control gate)被施加的电压。而数据的表示,以所存储的电荷的电压是否超过特定的阈值Vth来表示。
所以,对于FLASH的擦除,即对浮置栅极进行放电,低于Vth,就表示1,这也是浮栅层中被擦除的数据不可恢复的原因。擦除前后浮栅层的电荷变化如下图所示
02
软销毁方案
为满足不同客户的需求,我们提供了5种软销毁方案供客户选择,分别为数据销毁、快速销毁、CODE销毁、全盘销毁以及密钥销毁。
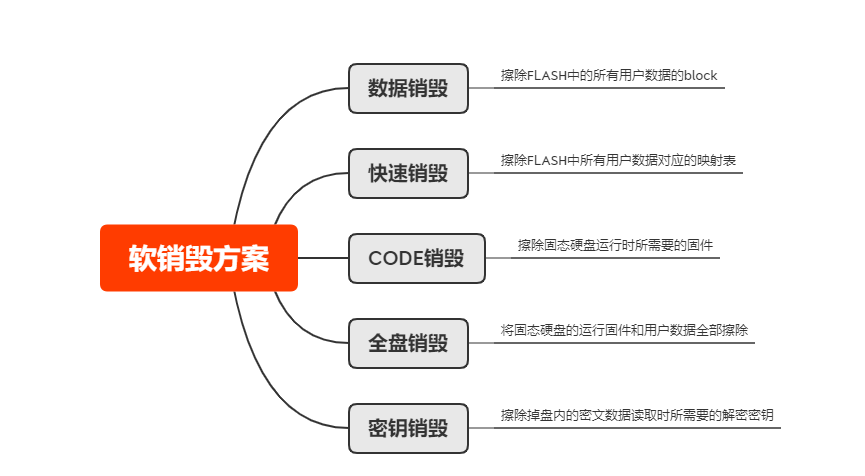
以2T大小的NVME盘为例,五种销毁方案也存在差异。(特点见下表)
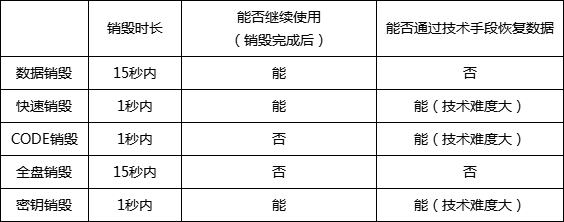
1. 数据销毁
SSD经过数据销毁后,盘经过初始化后可复用,但用户数据将不可恢复。我司固件擦除方案中对block的擦除并发度很高,实测全盘擦除时间几乎同等于根据FLASH芯片手册所计算的理论全盘擦除时间,所以擦除性能很高。
2. 快速销毁
快速销毁方案的特点是销毁速度快,无论是多大容量的盘,都可以保证销毁动作在1秒钟内完成,并且销毁完成后盘还可复用。
3. CODE销毁
CODE销毁同样将性能作为首选,保证销毁动作在1秒钟内完成,以应对紧急状态下需要使盘无法工作的情况,销毁完成后,必须通过SSD厂商介入重新开卡,设备才能重新使用。
4. 全盘销毁
SSD经过全盘销毁后,盘内部固件和用户数据将被一并擦除。销毁完成后设备无法工作,数据不可被恢复。
5. 密钥销毁
将SSD内部存储的密钥销毁后,主机从设备读出的密文将无法通过解密模块被正确解析出来,从而使盘内部所存储的所有数据失效。

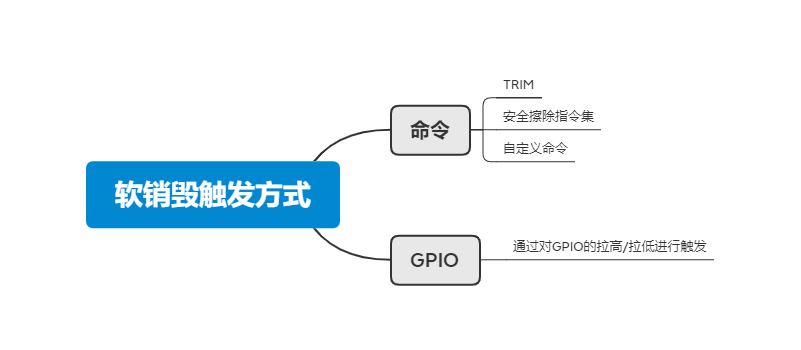
软销毁的触发方式有两种:命令和GPIO。见下图
03
总结
综上所述,我司可以通过更改固件的方式来完成不同方案的软销毁功能。
从安全和性能两个方面实现不同销毁程度的方案。从性能方面考虑,客户可以选择快速销毁、CODE销毁以及密钥销毁;从安全方面考虑,可供客户选择的有数据销毁和全盘销毁。
基于多源传感器的海量小文件存储与检索
提语:
海量多源传感器数据如何存储管理?
怎么从千万级海量数据中搜索到需要的数据?
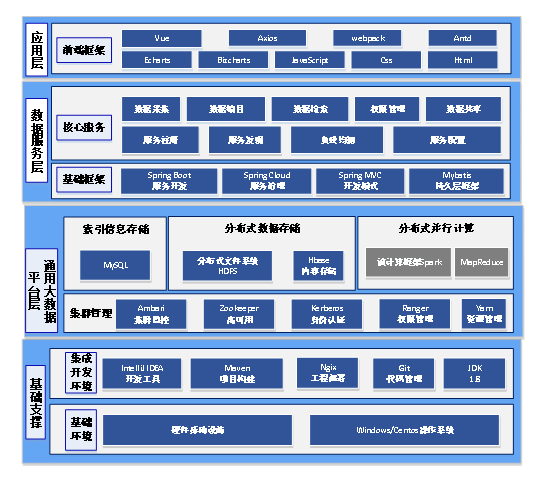
01 背景介绍 Background 分布式的大数据平台进行存储和检索的方式逐渐成为主流的主要原因是多源传感器数据具有种类繁多、大小不一、存储与检索困难等特点。传统的数据库和数据存储方案无法满足数据的存储、检索需求。大数据平台能够支持采用物理设备动态扩展资源,从而支撑数据量的线性增长。 基于多传感器的海量数据的存储与检索功能及性能需求,采用图中技术体系搭建大数据平台,实现分布式的数据存储和数据检索。
技术方案:
其技术体系架构主要分为以下几层: (1)基础支撑层 在相关硬件和操作系统的基础环境之上,采用IDEA作为开发环境,使用Maven管理项目内与项目间Jar包的依赖关系,使用Git作为项目管理和代码托管平台,基于Java JDK1.8进行整个项目的开发,Ngix用于部署运行编写完善稳定的代码。 (2)通用大数据平台层: 通过Ambari搭建大数据平台,更方便地管理各个组件的版本对应关系及集群整体健康状况。 基于Zookeeper实现大数据平台的高可用(HA),提高集群的可靠性。 通过Kerberos和Ranger实现数据的用户认证和权限管理,大数据平台管理系统的用户管理和权限管理功能基于该组件进行开发。 Yarn作为资源管理器,是一个通用资源管理系统,可为大数据平台上的应用提供统一的资源管理和调度。 HDFS是大数据管理系统开发的核心组件,主要用于存储各种文件,实现文件上传、下载、移动、复制等文件管理功能。 Mysql作为传统的关系型数据库,用于存储文件的索引信息,用于实现数据检索功能,同时作为系统的元数据库,存储大数据平台和管理系统的配置参数等信息。 Hbase作为一种大容量的可实时读写的列式分布式数据库,可用于后期存储文件内容,以便于对内容进行检索。 (3)数据服务层: 在通用大数据平台的基础上,根据业务需求基于Springboot对大数据平台各组件的API进行封装,开发Restful风格的后端接口,供前端页面调用。Springboot与Mybatis结合使用,通过XML或注解来配置和映射原生信息,可将接口和Java的POJO类映射成数据库中的记录。基于Springcloud可对开发的后端接口进行统一配置管理,如服务注册发现、负载均衡等,保证微服务的稳定性和可靠性。 (4)应用层:
主要用于前端页面的开发,在Js、Css、Html前端基本开发语言的基础上,采用React+Umi+Dva的前端框架,实现前后端分离的开发模式,通过传输统一的参数或Json数据实现数据交互。Antd是较为成熟的前端开源组件库,含有大量的前端组件,可以保证前端页面的统一风格。Echarts和Bizcharts是如今使用较多的开源图表库,包含多种多样的图表,可用于数据可视化展示。
02 关键技术 key 用户需要采集海量的传感器数据,并对多源传感数据用不同的算法进行处理以及对算法中的参数进行调整,因此会产生大量源数据、中间文件及结果文件。这些文件的大小不一,较小且比较重要,需要追加检索小文件,这种应用场景不适合一次写入多次读取的场景。大量的小文件会对元节点的内存造成较大压力,同时小文件过多造成存储系统的寻道时间过长大于读写时间,使得整个存储系统的读写缓慢。因此在大数据平台体系下解决小文件存储问题需要作为一个关键技术来进行研究。 常用的技术方案一般采用(1)-(3),通过数据打包后进行块存储来解决读写缓慢的问题,但都存在各自的缺陷或问题,不适用海量多源传感器的存储与检索应用,因此推荐方案(4)通过Hbase的rowkey方式来解决该技术问题。 (1)Archive小文件存储方案: Archive命令将文件系统的某个或多个目录下的小文件打包成以*.har为结尾的文件,该命令是通过MapReduce的方式合并文件,归档文件中包含元数据信息和小文件内容,即从一定程度上将元节点管理的元数据信息下沉到数据节点上的归档文件中,避免元数据的膨胀。但是该文件一旦创建就无法修改,因此不能在当前的基础上追加合并小文件,能够适应应用场景有限。 (2)SequenceFile小文件存储方案: SequenceFile本质上是一种二进制文件格式,类似key-value存储,通过编程将需要合并的小文件合并成一个以.seq为结尾的大文件(以文件名为key,文件内容为value)。这种方式的灵活性较高,可以选择要合并的小文件,但是.seq文件一旦生成也无法修改,无法追加合入新的小文件,如果当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的,同时二进制文件,合并后不方便查看。因此当前SequenceFile合并小文件也不适合当前的应用场景。 (3)CombinedFile存储方案: 其原理也是基于MapReduce将原文件进行转换,首先通过CombineFileInputFormat类将多个文件分别打包到一个split中,每个mapper处理一个split,提高并发处理效率,其优点是适用于处理大量比block小的文件和内容比较少的文件合并,尤其是文本类型/sequencefile等文件合并,其缺点是:如果没有合理的设置maxSplitSize,minSizeNode,minSizeRack,则可能会导致一个map任务需要大量访问非本地的Block造成网络开销,反而比正常的非合并方式更慢。因此这种小文件存储方案应用较少。 (4)Hbase小文件存储方案: HBase主要是key/value存储结构,一个key对应多个列族的多个列值。HBase可以很方便地将图片、文本等文件以二进制的方式进行存储。虽然HBase一般可以处理从1字节到10MB大小的二进制对象,但是HBase通常对于读写路径的优化主要是针对小于100KB的值。当HBase处理数据为100KB~10MB时,由于分裂(split)和压缩(compaction)会引起写的放大,从而会降低HBase性能。所以在HBase2.0+引入了MOB特性,这样保持了HBase的高性能、强一致性和低开销。MOB的出现大大提高了我们使用HBase存储小文件的效率,这样无须关注底层HDFS是怎么存储的,只要关注上层逻辑即可,HBase的强大优势也能保证存储的高可靠和稳定性,管理也方便。MOB还可以设置MOB压缩策略,为了减少MOB Files的数量以提升性能,HBase可以定期做MOB 压缩,默认是按天压缩,也可以修改成按星期或按月压缩。以文件路径+文件名为rewkey,以文件内容为cell。 小文件存储示意图
通过rowkey可以快速检索到文件,同时利用hbase的时间戳实现文件的删除、更新操作。因为Hbase的存储只支持文本,我们下载文件后原始文件里的格式会发生变化,为了保持原文件的格式,我们可以在上传文件的时候将文件流转换成BASE64的编码,这样上传和下载仍是原文件。为了web端的文件目录结构,在MySQL里存储一个用户目录的树形结构,通过MySQL将各种传感器的原始数据,图像数据和算法处理后的数据进行关联,用于信息检索。 03 小结 conclusion 通过本期的知识分享,大家了解到基于多源传感器的海量小文件存储和检索的技术体系、数据存储及检索的关键技术,可以更好地应对海量小文件的智能检索,帮助用户提取数据、分析数据,实现数据价值。
 扫一扫,了解更多
扫一扫,了解更多